3 novembre 2025

Quand l’IA bouscule l’accessibilité : le faux audit qui dit la vérité
Edit : découvrez notre nouveau site dédié à l’accessibilité : Frontguys A11Y Récit d’une campagne pédagogique qui a piégé… pour...
En novembre 2025, nous avons lancé chez notre client un chantier qu’il repoussait depuis plusieurs années : moderniser son outil interne le plus critique. Conçu en 2019 pour porter son cœur administratif, ce logiciel est indispensable au travail de collaborateurs internes comme d’utilisateurs externes. Tout dysfonctionnement de cette application entraîne des répercussions opérationnelles et économiques immédiates.
Sur le papier, le chantier semblait relativement clair : moderniser une application Angular historique, l’aligner avec le Design System de l’entreprise, harmoniser son architecture et sécuriser ses évolutions futures. En pratique, nous allions découvrir que la dette accumulée n’était pas seulement technique. Elle était aussi cognitive : une partie importante de la connaissance métier n’existait qu’à travers un code devenu difficilement lisible.
C’est dans ce contexte que nous avons commencé à utiliser l’IA générative. Non pas pour remplacer le travail d’analyse ou de conception, mais pour nous aider à comprendre, transformer et sécuriser un système devenu trop volumineux pour être repris manuellement dans des délais raisonnables.
Les symptômes étaient connus depuis longtemps. L’application ne pouvait pas intégrer le Design System de l’entreprise, ce qui créait un écart croissant avec les autres outils internes. Les nouvelles fonctionnalités devenaient difficiles à estimer, les développeurs chiffraient chaque user story, même les mises à jour minimes, avec une forte marge d’erreur, à cause de la complexité de l’application. Certaines zones du code étaient abordées avec prudence, certaines interventions réservées aux profils les plus expérimentés, de peur d’introduire des régressions.
Cette peur de “casser quelque chose” est souvent l’un des signaux les plus nets d’une dette technique installée. Elle ne signifie pas que les équipes manquent de compétence. Elle signifie plutôt que le système ne donne plus assez de garanties à celles et ceux qui le font évoluer. Quand un changement local peut avoir des conséquences imprévisibles ailleurs, chaque modification devient une prise de risque. Les mises à jour techniques avaient ainsi été repoussées à plusieurs reprises, jusqu’à atteindre cinq versions majeures de retard sur Angular mi-2025, exposant le projet à des failles de sécurité.
Vous vous en doutez, une telle situation n’est pas le résultat d’une seule mauvaise décision. Elle venait d’un combo classique alliant disparition des sachants et absence de traçabilité des choix : rotation importante des développeurs leads et seniors, perte progressive de connaissance métier, peu de documentation, plusieurs générations de pratiques Angular, absence de standards réellement homogènes. Chaque choix avait probablement une justification à son époque. Mais six ans plus tard, l’ensemble formait un système opaque et coûteux à maintenir.
La taille du projet expliquait une partie de cette difficulté à le maintenir à jour. L’application comptait 212 composants, autant de styles SCSS, 8 API différentes et de nombreux modèles métier. L’objectif n’était pas seulement de “mettre à jour Angular”, il s’agissait de moderniser en profondeur la manière dont l’application était construite. Nous voulions remplacer les composants historiques par ceux du Design System, utiliser les design tokens sur l’ensemble des pages, afin d’harmoniser l’interface avec les autres produits de l’entreprise et profiter des apports du Design System en matière d’accessibilité, de performance et de cohérence.
Un autre objectif était tout aussi important : rendre le code testable. Au fil des années, les appels aux API, les calculs de règles métier, la gestion des événements utilisateur et le rendu de l’interface s’étaient souvent retrouvés entremêlés dans les mêmes fichiers, les rendant très volumineux, les plus critiques dépassaient les 1000 lignes de code. Pour sécuriser durablement l’application, il fallait séparer ces responsabilités: les calculs métier devaient pouvoir être testés indépendamment de l’interface, la logique d’affichage devait cesser de porter des règles métier implicites.
Nous voulions offrir à l’équipe de développement la sérénité qu’il lui manquait.
Cette partie du chantier fera l’objet d’un article plus technique, car elle mérite d’être détaillée avec des exemples et des chiffres. Mais elle est essentielle pour comprendre la suite : sans restructuration, il était presque impossible de garantir que les évolutions futures n’introduiraient pas de régression. Nous voulions offrir à l’équipe de développement la sérénité qu’il lui manquait.
Le plus grand problème n’était pas seulement la taille de l’application. C’était la compréhension du métier. Le cœur du produit reposait sur un formulaire central composé de 18 sous-formulaires et de plus de 200 champs. Certains champs apparaissaient ou disparaissaient selon les informations remplies. D’autres devenaient obligatoires dans des contextes précis. À cela s’ajoutaient plus de 30 variantes d’une entité métier clé, de nombreuses sous-catégories, 7 profils utilisateurs, 12 états de workflow et des règles de validation dépendant à la fois du rôle de l’utilisateur, de l’état du dossier et des données déjà saisies.
Ces règles n’étaient pas documentées. Le code était devenu l’unique source de vérité.
C’est une situation fréquente dans les applications internes anciennes. Le métier évolue, les développeurs changent, les arbitrages s’accumulent, et la documentation reste rarement à jour. Progressivement, les règles finissent par être connues uniquement du système lui-même. Elles existent dans des conditions, des branches, des noms de variables, des appels de services, parfois dans des morceaux de code ajoutés plusieurs années plus tôt pour répondre à un cas particulier.
Pour moderniser l’application, nous devions donc d’abord comprendre ce qu’elle faisait réellement. Pas ce qu’elle était censée faire. Ce qu’elle faisait, effectivement, dans tous les cas particuliers.
Les premières phases de refactoring ont rapidement montré les limites d’une approche classique. Les estimations étaient régulièrement dépassées, chaque ticket de refactoring semblait en cacher plusieurs autres. Une modification apparemment locale révélait une dépendance inattendue, un comportement non documenté ou un cas métier oublié. Certains chantiers ressemblaient à des poupées russes, derrière chaque problème résolu se cachait un autre problème, puis un autre encore.
Dans ce contexte, les régressions devenaient difficiles à éviter. Nous n’étions pas incapables de refactoriser. Nous savions ce qu’il fallait faire. Mais le volume de transformations répétitives, combiné à la quantité de règles métier implicites, rendait le chantier difficile à sécuriser et encore plus difficile à planifier. Il devenait impossible de donner aux équipes de Product Management une date de fin réellement fiable. C’est à ce moment-là que l’IA est devenue utile.
Notre premier usage de l’IA a été très pragmatique : automatiser les parties répétitives du refactoring. Une fois quelques composants migrés manuellement, nous pouvions fournir à l’IA des exemples avant/après et lui demander d’appliquer les mêmes transformations ailleurs. Migration vers les Signaux, renommages, réorganisation de fichiers, suppression de duplications, remplacement de composants locaux par ceux du Design System : ces tâches restaient à relire, mais elles n’avaient plus besoin d’être entièrement écrites à la main.

Le gain n’était pas seulement un gain de vitesse. L’IA permettait aussi d’absorber la monotonie d’un chantier qui aurait sinon demandé de répéter des centaines de fois les mêmes gestes, avec le risque humain que cela implique : fatigue, oublis, incohérences entre deux composants pourtant similaires.
Son deuxième apport a été la compréhension du code existant. Dans un système aussi imbriqué, répondre à une question simple pouvait nécessiter de parcourir plusieurs composants, services et sous-formulaires. L’IA nous a aidé à suivre ces connexions plus rapidement. Nous pouvions lui demander pourquoi un champ apparaissait ou devenait obligatoire, quels services intervenaient dans un workflow, quels composants dépendaient des données d’un autre. Nous avions une meilleure vision de l’impact de chaque modification.
L’IA ne remplaçait pas l’analyse humaine, elle accélérait l’exploration. Là où nous aurions passé du temps à reconstruire mentalement une arborescence, elle nous fournissait une première cartographie que nous pouvions ensuite vérifier.
Dans un projet idéal, nous aurions commencé par écrire des tests automatisés décrivant le comportement attendu de l’application avant de modifier le code. Cette approche, appelée Test Driven Development, ou TDD, consiste à écrire les tests avant l’implémentation. Elle permet normalement de sécuriser les évolutions : si une modification altère un comportement existant, les tests l’indiquent immédiatement. Mais dans notre cas, cette méthode n’était pas applicable au début du chantier.
Le code n’était pas suffisamment découpé pour cela. Les règles métier étaient souvent mélangées avec le rendu de l’interface et les appels aux API. Tester une règle isolée supposait parfois d’instancier un composant complet, de simuler une interface, de préparer des données complexes et de contourner des dépendances techniques nombreuses. Autrement dit, les tests unitaires auraient été trop coûteux à écrire et trop fragiles pour vraiment sécuriser le refactoring.
Nous avons donc utilisé l’IA autrement. Nous avons commencé à détourner la fonctionnalité de revue de code de Codex, qui permet de comparer une branche à une autre. Concrètement, nous lui donnions accès simultanément à la version historique du code et à sa version refactorisée, en lui demandant de concentrer son analyse uniquement sur les aspects fonctionnels.
Plutôt que de lui demander de produire du code, nous lui demandions d’agir comme un auditeur.
Son rôle consistait à analyser les différences entre les deux implémentations et à signaler les écarts susceptibles de modifier le comportement attendu de l’application : règles de validation disparues, conditions modifiées, comportements particuliers oubliés ou cas qui n’auraient pas été repris dans la nouvelle version.
L’outil produisait alors un rapport détaillé que nous analysions ensuite de manière critique. Certaines remontées étaient pertinentes, d’autres constituaient des faux positifs. Comme pour le reste du chantier, l’IA ne prenait aucune décision à notre place : elle mettait en évidence des points d’attention, mais l’analyse finale restait entre les mains de l’équipe.
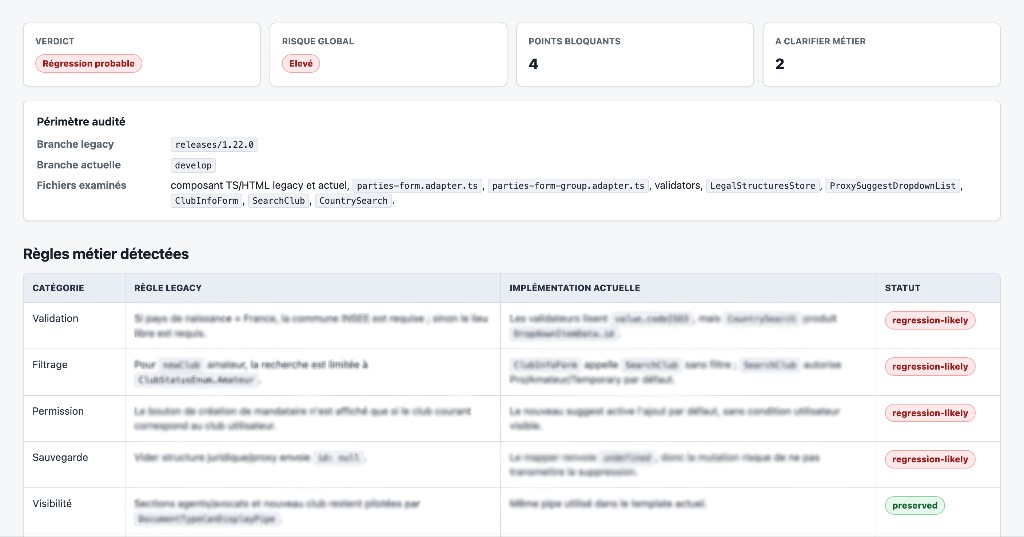
J’aime appeler cette pratique des “tests fonctionnels conversationnels”. Ce n’étaient pas de vrais tests unitaires, puisqu’ils ne s’exécutaient pas automatiquement dans le projet. Mais ils jouaient un rôle proche dans notre processus : détecter des différences de comportement avant qu’elles ne deviennent des régressions visibles.
Par exemple, l’IA pouvait repérer qu’un champ devenait disabled dans certaines conditions dans l’ancienne version, alors que cette condition n’apparaissait plus dans la version refactorisée. Elle ne pouvait pas décider seule si la différence était acceptable. En revanche, elle nous signalait une zone à vérifier. Elle ne garantissait pas l’absence de régression, mais elle attirait régulièrement notre attention sur des différences que nous n’aurions probablement pas repérées lors d’une simple revue de code.
L’IA n’a pas “sauvé” le projet par magie. Elle a été efficace parce que nous avons construit un cadre autour d’elle.
Le premier élément déterminant a été le Design System de l’entreprise. Il était déjà mature, documenté dans Storybook, et chaque composant exposait clairement ses propriétés, ses usages et ses exemples. L’IA pouvait donc s’appuyer sur une référence stable. Plus la documentation d’un composant était claire, plus les propositions générées étaient pertinentes.
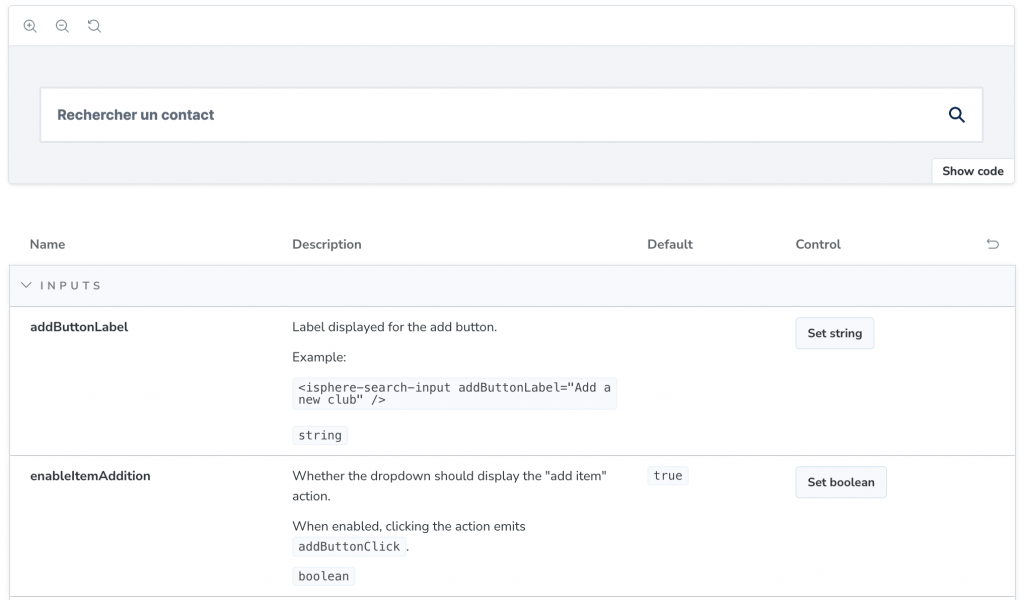
Mais l’utilisation des composants du Design System n’était qu’une partie de notre chantier, la plus simple et la plus répétitive. Il fallait également apprendre à l’IA comment transformer le code historique qui l’entourait.
Nous avons d’abord refactorisé à la main plusieurs modules représentatifs. Au départ, l’IA était loin d’être aussi efficace que nous l’espérions. Comme souvent, elle avait tendance à reproduire les patterns déjà présents dans la codebase. Si l’existant est confus, elle risque davantage d’en prolonger la confusion que de la corriger.
Mais plus le chantier avançait, plus le dépôt contenait d’exemples de composants déjà modernisés, prêts à servir de référence aux modèles. Codex et Claude pouvaient alors s’appuyer sur un nombre croissant de cas concrets pour comprendre nos conventions, nos choix d’architecture et notre manière d’utiliser le Design System.
Les premiers composants refactorisés demandaient beaucoup de corrections manuelles. Quelques mois plus tard, l’IA disposait déjà de dizaines d’exemples couvrant des contextes variés : formulaires complexes, modales, listes, workflows ou encore différents profils utilisateurs. Les transformations sont alors devenues plus fiables, non pas parce que les modèles avaient changé, mais parce que la codebase elle-même était devenue une meilleure source d’apprentissage. Un cercle vertueux s’est ainsi installé : chaque composant modernisé enrichissait le corpus de référence disponible pour les suivants.
Cette amélioration progressive ne signifie pas pour autant que l’IA devenait autonome. Même dans une codebase assainie et riche en exemples, elle devait rester fortement cadrée. Nous avons observé une tendance des modèles à complexifier le code à outrance lorsque la demande était trop large. Plus le périmètre était important, plus le risque augmentait : modifications involontaires de règles métier, oublis de comportements existants ou propositions difficiles à relire et à valider.
Pour limiter ce problème, nous avons progressivement découpé nos usages en Skills spécialisés : un Skill pour les formulaires, un autre pour les modales, un autre pour la migration vers les Signaux, un autre encore pour déplacer, découper et réorganiser les fichiers. Ce découpage avait deux avantages. D’abord, il réduisait la quantité de contexte inutile envoyée à chaque demande, ce qui permettait de mieux maîtriser la consommation de tokens. Ensuite, il rendait les réponses plus ciblées, plus faciles à relire et plus cohérentes avec le type de transformation attendu.

Nous avons rencontré une limite plus insidieuse. À plusieurs reprises, l’IA a identifié certaines portions du code comme inutilement complexes et a proposé de les simplifier. Dans la plupart des cas, ces suggestions étaient pertinentes. Mais sur un projet accumulant plusieurs années d’historique, certaines incohérences apparentes sont en réalité les traces visibles de contraintes oubliées.
L’IA a ainsi cherché à simplifier une implémentation qui semblait inutilement compliquée, introduisant une régression non détectable par nos « tests fonctionnels conversationnels ». Pourtant, cette logique répondait à une règle importante dont la justification n’apparaissait nulle part dans le système. Elle n’avait commis aucune erreur de raisonnement : elle avait simplement travaillé à partir des informations visibles dans le système. La règle qui justifiait cette complexité n’était documentée ni dans le code, ni dans les tests, ni dans la documentation. Elle survivait uniquement dans la connaissance implicite de certains développeurs.
Bien sûr, le chantier a produit des résultats tangibles. En six mois de développement effectif, nous avons remplacé l’ensemble des composants historiques, généralisé l’utilisation du Design System, ajouté des tests sur les règles métier critiques et modernisé une application qui accusait plusieurs années de retard technique.
Mais avec le recul, ce n’est pas ce que nous retenons principalement de cette expérience. La valeur apportée par l’IA n’a pas seulement été de nous faire gagner du temps. Elle nous a surtout permis de rendre le chantier supportable. Elle a absorbé une grande partie du travail répétitif. Elle nous a aidé à naviguer dans une codebase devenue difficile à comprendre. Elle nous a permis de vérifier plus rapidement les impacts de certaines modifications. Elle nous a offert des filets de sécurité là où il n’en existait pratiquement aucun.
Sur un projet de cette taille, la difficulté n’est pas uniquement technique. Elle est aussi psychologique. Répéter les mêmes transformations des dizaines de fois, découvrir sans cesse de nouveaux cas particuliers, corriger des régressions et avancer sans savoir quand le chantier prendra fin finit par peser sur les équipes. L’IA n’a pas supprimé cette complexité. En revanche, elle nous a aidés à la rendre gérable.
La valeur apportée par l’IA n’a pas seulement été de nous faire gagner du temps. Elle nous a surtout permis de rendre le chantier supportable.
Quelques semaines seulement après la fin du chantier, nous constations déjà un gain significatif de vélocité pour faire évoluer les règles métier du produit. Mais surtout, les équipes avaient retrouvé quelque chose qui s’était progressivement perdu au fil des années : la confiance dans leur capacité à faire évoluer l’application sans craindre en permanence les effets de bord. C’est probablement le véritable objectif d’un projet de modernisation : non pas produire une architecture parfaite, mais redonner aux équipes la capacité de faire évoluer leur produit sereinement.

